割り算アルゴリズムその2
- 単項式を消していく事で,割り算を実現
- 多項式の割り算は,単項式を少しずつ消していく
- (順序が重要)
——–
はじめに?
「割り算アルゴリズム」で一記事にしようとしていましたが,長くなってしまったので分割しました.この記事では,多項式の割り算を扱っていきます.
理論
準備(前提知識)
- 単項式,多項式
- 係数
- 順序
- 簡単な割り算アルゴリズム(前記事)
目標(理論)
最終的には,多項式と多項式で割り算をすることが目標です.
複雑な例への準備
もし,余り
これは,例えば式 
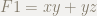
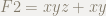
これを式にして表現してみます.
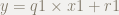
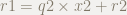
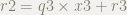

は,割られる式です.
は,商です.
は,割る式です.
は,余りです.
上の式では,1行目で計算した余り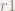
なので,余りをさらに割ります.また余りが割れるなら・・・という計算です.
とても簡単な例で同じ計算をしてみます.

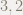
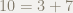


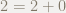
頭の悪そうな計算をしていますが,この例のように,もし余りがさらに割れるならさらに割る,ダメなら終了という流れが想像できると嬉しいです.
多項式の割り算はどうなるか(本題)
ここでようやく本題ですが,多項式と多項式で割り算することを考えます.
今までのことを使います.つまり,
- 割るには,(次数と係数を揃えて)引いて消す操作が必要
- 余りが出て,余りがさらに(他の式でも)割れるなら割る
つまり,多項式中の単項式を引いて消し,余りが出たら,他の単項式を引いてさらに消す.ということです.単項式を消していけば,いずれ割れなくなるはずです(※本当は停止性について考える必要があります).
では具体的な例を考えます.

説明都合上F2から割ります.すなわち,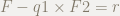
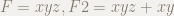



余りの 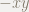
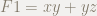

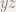
ん?本当に計算終了なの?
となります.が,消せないようです.
仮に,消したとすると,新しい式ができ,また消すことができ・・・と無限に操作できてしまいます.答えがあったとしても,答えかどうか判定もできないですし,答えに到達できるかも不明になります.
ここで,順序および単項式の大きさが重要になるはずです.あらかじめ大きさがわかっていて,大きいもので消していけば,この点が解決されるはずです(下記,自身の無い事を参照).
割り算結果が一意でない
先ほどの例ですが,実はF1から割ると,F2から割るときと結果が異なります.
F1で割ると,
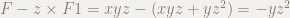
となり,結果が異なります.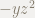
このように一般には複数の多項式で割ると,結果が一意に定まらないです.
この結果を一意に定めるには,F1,F2がグレブナ基底である必要があります.
また,結果を一意に定める多項式の集合がグレブナ基底です.
自信の無い事(理論)
私自身,書き出したはいいものの,よく理解できてないことです.
すなわち勉強不足な点です.
なぜ大きいものから割っていくのか
前提というか,基本的に割り算のアルゴリズムでは,大きいものから割っていきます.
なぜ大きい物から割っていく必要があるのか?なのですが,正直理解できてないです.直感的には,大きい方から割る方が無駄がなさそう(計算回数が少なそう)なので,大きい方から割ることは自然にも思えますが,なぜと問われると説得力がないです.
文章を作る時に浮かんだことですが,停止性のあたりと関係ありそうです.
私が停止性をちゃんと把握できてないので,そこで理解ができていないと考えられます(要勉強).
係数がなぜ重要なのか
また,このタイプのアルゴリズムでは,おそらく,係数が重要です.
というのも,係数が固定されてないと無理やり割っても何とかなるためだと思います.
上記説明のアルゴリズムでなければ,無理やり 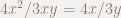
このとき,係数に着目すると,整数から有理数に係数が変化しています.
上記の割り算アルゴリズムなら,その心配はないはずです(整数-整数=整数となるはずです).
なぜ係数を固定する必要があるのか?という点は理解が足りてないですが,問題設定上係数を固定することが多いように見られます.係数を固定しているならば,無理やり割る事ができない,というわけだと思います.
プログラム
今回はプログラムというより電卓です.足し算引き算して,理論の内容が実装できているように見えればOKという感じです.
次に、多項式での割り算,割る順序で結果が異なる例を計算しています.
多項式の割り算
// 割り算アルゴリズム2
print("コード見ながらの実行を推奨します。")$
print("もしくは、対話モードで実行を推奨します。")$
F1 = x*y + y*z$
F2 = x*y*z + x*y$
F = x*y*z$
/*
// example2
F = xyz を割る
F1 = xy + yzから割り始める
xyz - (w)*(xy + yz)
[...wは適当な値、変数(つまりwは単項式)]
w = z
とすれば、
xyz - (xyz + yz^2) = -yz^2
となって、F = xyz を消せそう
また、-yz^2をF1,F2で消せない。計算終了となる。
*/
R1 = F - z*F1;
// R1 = -y*z^2
/*
// example2
同じく、F = xyz を割る
ただし、F2 = xyz + xyから割り始める
xyz - (w)*(xyz + xy)
[...wは適当な値、変数(つまりwは単項式)]
w = 1
とすれば、
xyz - (xyz + xy) = -xy
*/
R2 = F - F2;
// R2 = -xy
/*
ここでさらに、F1 = xy + yz なので、まだ割れる
-xy - (v)*(xy + yz)
[...vは適当な値、変数(つまりvは単項式)]
v = -1
とすれば、
-xy + xy + yz = yz
となって、-xy が消せそう
*/
R3 = R2 - (-1)*F1;
// R3 = yz
end$
